LLM開発者のための継続事前学習と教師ありファインチューニング基本ガイド
大規模言語モデル(Large Language Models, LLM)の研究開発が急速に進む現在、Llama, Mistral, Gemmaを始めとした数多くの事前学習済みモデル(基盤モデル)が公開され、誰でも利用可能となっています。多くの計算資源を必要とするLLMの開発においては、これらの基盤モデルを出発点として活用することがコスト効率の高いアプローチとなっています。既存のモデルを特定のタスクや領域に適応させる場合、「継続事前学習(Continual Pre-training, CPT)」と「教師ありファインチューニング(Supervised Fine-tuning, SFT)」という二つの主要な手法が存在します。これらの手法は目的や利用するデータの性質が異なるため、適切な使い分けが必要です。
本記事では、継続事前学習と教師ありファインチューニングの違いを体系的に解説し、リソース制約や目的に応じた適切な学習設計の指針を提供します。
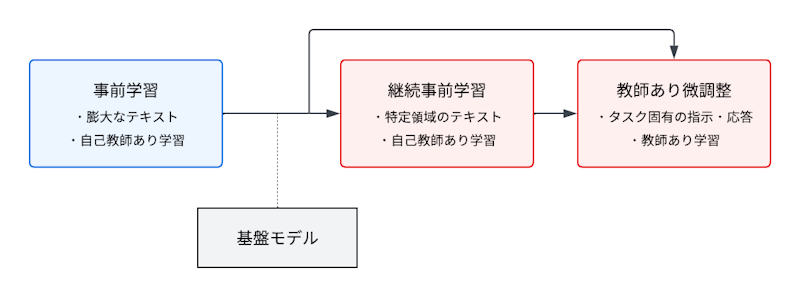 図:LLMの学習ステップ
図:LLMの学習ステップ
前提:事前学習の基礎
まず、継続事前学習と教師ありファインチューニングを理解する前提として、事前学習(Pre-training)の基本概念を確認しておきましょう。
自己教師あり学習としての事前学習
LLMの事前学習は、基本的に自己教師あり学習(Self-supervised Learning)のパラダイムに基づいています。これは、ラベル付きデータを必要とせず、入力データ自体から教師信号を生成する学習手法です。現在、文章生成に使われるLLMの多くでは、主に「次トークン予測(Next Token Prediction)」タスクが用いられます。
例えば、「今日の天気は」という入力に対して、次に続く「晴れ」という単語を予測するタスクです。モデルは与えられた文脈から次に現れる可能性が高い単語を予測することを学習します。
入力: "今日の天気は"
予測目標: "晴れ"
このようなタスクを大量のテキストデータに対して行うことで、モデルは言語の統計的パターンを学習し、単語の意味や文法構造、さらには世界知識まで獲得していきます。このプロセスは、人間による明示的なラベル付けを必要とせず、テキストデータさえあれば自動的に学習信号を生成できます。つまり、インターネット上の膨大なテキストデータから、モデル自身が「入力と予測すべき次の単語」というペアを作り出して学習できるのです。
事前学習の意義と限界
事前学習の最大の利点は、特定のタスクに依存しない汎用的な言語理解能力を獲得できることです。一度事前学習を行えば、その後様々なタスクに転用できるため、非常に効率的なアプローチと言えます。また、ラベル付きデータが少ない領域でも、事前学習によって獲得した一般的な言語理解能力を活かすことができます。
しかし、事前学習には以下のような限界も存在します。
知識の最新性: 事前学習データの収集時点で学習が終了するため、新しい情報を取り込めません。例えば、2024年までのデータで訓練されたモデルは、2025年以降の出来事については知識を持ちません。
ドメイン特化知識の不足: 汎用的なウェブテキストでは、特定の専門分野の知識が十分に含まれていないことがあります。そのため、専門分野に関する言語理解や知識が不足する場合があります。
特定タスクへの最適化不足: 自己教師あり学習では、次トークン予測という一般的なタスクに対して最適化されるため、質問応答や要約など特定のタスクに対しては最適な性能を発揮できない場合があります。
これらの限界を克服するために、継続事前学習と教師ありファインチューニングという二つのアプローチが重要な役割を果たします。これらの手法により、事前学習済みのモデルをさらに特定の目的や領域に適応させることが可能になります。これから2つの手法の詳細を見ていきましょう。
継続事前学習(Continual Pre-training, CPT)
継続事前学習は、既に事前学習済みのモデルに対して追加のデータを用いて、事前学習と同じく自己教師あり学習のパラダイムで学習を継続する手法です。
継続事前学習の目的
継続事前学習の主な目的は以下の通りです。
- ドメイン適応: 特定の専門分野(医療、法律、金融など)のテキストで追加学習し、その分野の言語的特徴を学ばせる
- 最新情報の取り込み: 新しい出来事や知識を反映した最新のテキストデータで学習を継続する
- 多言語能力の拡張: 特定の言語に関するデータで追加学習し、その言語での能力を向上させる
重要な点は、継続事前学習では元の事前学習と同じ学習目標(主に次トークン予測)を使用することです。つまり、自己教師あり学習の枠組みを維持しています。
継続事前学習のポイント
継続事前学習を実施する際の重要なポイントは以下の通りです。
データ選択
- 目的に応じた高品質なデータを準備(例:特定ドメインの専門書や論文、最新のニュース記事など)
- データの重複や偏りに注意し、バランスの取れたコーパスを構築
ハイパーパラメータ設定
- 学習率:一般に元の事前学習よりも小さい学習率を設定(例:1e-5 〜 5e-5程度)
継続事前学習の課題
継続事前学習を実施する際には、いくつかの重要な課題に対処する必要があります。
破滅的忘却(Catastrophic Forgetting): 新しいデータに適応する過程で、元の学習で獲得した知識や能力が失われる現象です。これは特に対象ドメインが元の事前学習データと大きく異なる場合に顕著に現れます。例えば、専門的な医療テキストで継続事前学習を行うと、一般的な会話能力が低下する可能性があります。
計算コスト: 大規模モデルの場合、継続事前学習には相当な計算リソースが必要です。特に数十億から数千億パラメータを持つモデルでは、継続事前学習の実施には高性能なGPUクラスタが必要となり、コストと時間の面で大きな制約となることがあります。
データバランス: 新たなドメインデータに過度に適応すると、モデルの汎化性能が低下するリスクがあります。継続事前学習で使用するデータセットは、特定のドメインの特徴を学ぶのに十分な特殊性を持ちながらも、過度に偏ったものにならないよう注意深く構築する必要があります。
これらの課題に対処するためには、以下のような手法やアプローチが検討されています。
適切なデータ混合比率の設定: 新しいドメインデータと元の事前学習データの一部を適切な比率で混合することで、破滅的忘却を軽減しながら新しい知識を取り込むことができます。
知識蒸留の活用: 継続事前学習の前後でモデルの出力を比較し、元のモデルの知識を保持するような正則化を加えることで、重要な能力の喪失を防ぐことができます。
段階的な学習率減衰: 学習の初期段階では比較的高い学習率を設定し、徐々に減衰させることで、新しい知識の取り込みと既存知識の保持のバランスを取ることができます。
継続事前学習の効果を最大化するには、これらの課題を認識し、適切な対策を講じることが重要です。特に大規模なプロジェクトでは、小規模な実験で最適なアプローチを見つけてから本格的な学習を開始することが推奨されます。
教師ありファインチューニング(Supervised Fine-tuning, SFT)
教師ありファインチューニングは、事前学習済みモデルに対して、特定のタスク向けにラベル付きデータを用いて追加学習を行う手法です。
教師ありファインチューニングの目的
教師ありファインチューニングは、事前学習済みモデルに対して、特定のタスク向けにラベル付きデータを用いて追加学習を行う手法です。この手法の主な目的は以下の通りです。
- タスク特化: 特定のタスク(質問応答、要約、対話など)に対してモデルの性能を最適化する
- 特定の出力スタイルの獲得: 望ましい応答形式や文体を学習させる
- アライメント: 人間の価値観や選好に沿った出力を生成できるよう調整する
継続事前学習との大きな違いは、教師あり学習の枠組みを採用している点です。つまり、入力と期待される出力のペアを用いて学習を行います。教師ありファインチューニングは主に「どう応答するか」のパターンを強化するもので、モデルがすでに持っている知識を適切な形式で出力することを学習させます。ただし、モデルが元々持っていない知識を新たに獲得することは期待しにくい点に注意が必要です。
教師ありファインチューニングの実装方法
データ形式
教師ありファインチューニングでは、以下のような形式のデータセットを用意します:
入力: "今日の東京の天気を教えてください"
期待される出力: "今日の東京は晴れで、最高気温は25度、最低気温は18度の予報です。"
このようなデータを多数用意し、モデルが適切な応答を生成できるよう学習させます。
ハイパーパラメータ設定
- 学習率:継続事前学習よりもさらに小さい学習率が一般的(例:1e-6 〜 1e-5程度)
教師ありファインチューニングの課題
教師ありファインチューニングには以下のような課題があります。
- 過学習のリスク: 特にデータ量が少ない場合、学習データに過度に適応してしまう
- 汎化性能の低下: 特定タスクへの最適化により、他のタスクでの性能が低下する可能性
- 高品質データの確保: 良質な教師データの作成には時間とコストがかかる
これらの課題を理解し、適切に対処することが重要です。教師ありファインチューニングの特性と限界を正確に把握した上で、プロジェクトの目標に合わせた適切な学習目的の設定や戦略の立案が効果的なモデル開発につながります。
継続事前学習と教師ありファインチューニングの使い分け
目的に応じた選択基準
継続事前学習と教師ありファインチューニングの選択は、プロジェクトの目的や対象領域の特性に大きく依存します。それぞれのアプローチが特に効果を発揮する状況について理解することで、より効率的な学習設計が可能になります。以下では、それぞれの手法が適している典型的なケースを解説します。
継続事前学習が適している場合
ドメイン知識の獲得が主目的: 特定分野の専門的言語や知識体系を学ばせたい場合。例えば、医療や法律などの専門分野では、一般的な事前学習データには含まれていない専門用語や概念が多数存在します。こうした知識をモデルに取り込むためには継続事前学習が効果的です。
モデルの知識を更新したい: 最新情報や変化した事実を反映させたい場合。LLMは事前学習データの収集時点までの情報しか持ち合わせていないため、新しい出来事や最新の知見を反映させるには、継続事前学習が必要です。
大量の教師なしデータが利用可能: ラベル付きデータが少ないが、対象ドメインの生テキストが大量にある場合。専門分野のテキストコーパスは比較的収集しやすいものの、質問-回答ペアなどの教師ありデータの作成には時間とコストがかかります。
教師ありファインチューニングが適している場合
特定のタスク性能を求める: 質問応答や要約など特定のタスクで高性能を求める場合。継続事前学習だけでは、モデルが特定の入力形式に対して望ましい形式で応答するとは限りません。特定のタスク形式に沿った出力を得るためには教師ありファインチューニングが不可欠です。
特定の応答スタイルを求める: 指示に従った特定の形式や文体での出力を求める場合。例えば、企業の対話システムで一貫した応答スタイルを実現したい場合や、特定の形式(例:箇条書き、表形式など)で回答を得たい場合が該当します。
高品質なラベル付きデータが利用可能: 入力と期待出力のペアが十分に用意できる場合。質の高い教師データがあれば、それを活用して直接的にモデルの応答パターンを最適化できます。
継続事前学習と教師ありファインチューニングは「知識獲得」と「タスク最適化」という異なる強みを持っており、プロジェクトの要件に応じて適切な手法を選択することが重要です。
ハイブリッドアプローチ
実際の多くのプロジェクトにおいては、継続事前学習と教師ありファインチューニングを単独で使用するよりも、これらを組み合わせたハイブリッドアプローチがよく用いられます。このアプローチでは、それぞれの手法の利点を活かしながら、より包括的なモデルの適応を実現できます。
典型的なハイブリッドアプローチは以下の2段階のプロセスで構成されます。
- まず継続事前学習で対象ドメインの知識と言語的特徴を獲得
- 次に教師ありファインチューニングで特定タスクに最適化
このような段階的アプローチにより、「知識獲得」と「タスク最適化」の両方を効果的に実現できます。例えば、医療分野の質問応答システムを開発する場合、まず医学論文や教科書などの大量のテキストで継続事前学習を行い、その後、医療質問と回答のペアデータを用いて教師ありファインチューニングを実施します。
実践的なガイドライン
計算リソースによる戦略の違い
実際の研究開発環境では、計算リソース、時間、予算などの制約が常に存在します。こうした制約条件下での効率的な学習戦略の選択は、プロジェクトの成功に直結する重要な意思決定となります。以下では、リソース制約のレベルに応じた推奨アプローチを解説します。
極めて限られたリソース: 少量の教師ありデータでのファインチューニングに集中することが最も効率的です。継続事前学習は大量の計算リソースを必要とするため、GPUの利用が制限されている環境では、厳選された高品質な教師データによるファインチューニングが現実的な選択肢となります。また、Parameter-Efficient Fine-Tuning (PEFT)手法を活用することで、さらに効率的な学習が可能になります。
中程度のリソース: 小規模な継続事前学習の後に教師ありファインチューニングを行うバランスの取れたアプローチが推奨されます。例えば、対象ドメインの重要なテキストを選別して短期間の継続事前学習を行った後、タスク特化のファインチューニングに移行する方法が効果的です。この場合、継続事前学習のステップ数や対象データ量を適切に制限することで、合理的な計算コストでの実装が可能になります。
豊富なリソース: 大規模な継続事前学習の後に教師ありファインチューニングを行うことで、最大限の性能向上が期待できます。複数のGPUを長期間利用できる環境では、大量のドメイン特化データでの継続事前学習を十分に行い、その後高品質な教師データでのファインチューニングを実施することが理想的です。
リソース制約の評価に際しては、単に利用可能なハードウェアだけでなく、プロジェクトのタイムラインや優先度も考慮に入れることが重要です。短期間での成果が求められる場合は、より即効性のあるアプローチを選択し、長期的なプロジェクトでは段階的に学習を進めていく戦略も検討に値します。
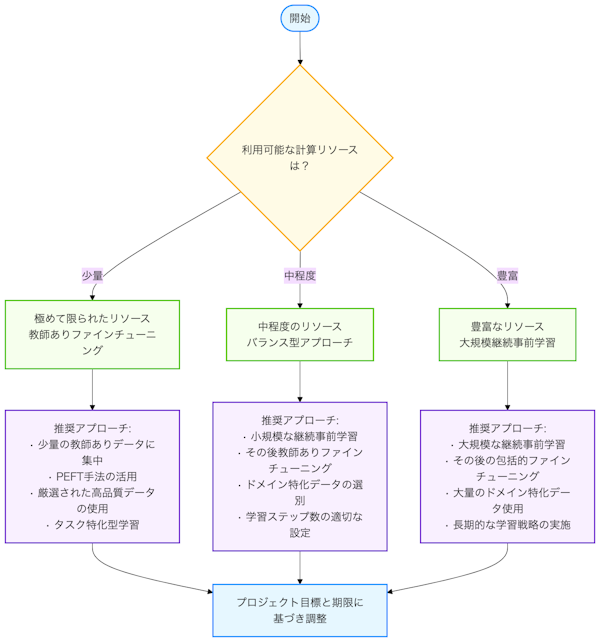 図:計算リソースによる学習戦略
図:計算リソースによる学習戦略
モデルサイズによる戦略の違い
モデルサイズは学習戦略を決定する上で重要な要素の一つです。パラメータ数によって学習の挙動や必要なリソースが大きく異なるため、モデルサイズに応じた最適な戦略を選択することが効率的な学習のカギとなります。以下では、サイズ別の戦略について詳しく解説します。
小規模モデル
- 計算コストが低いため、継続事前学習と教師ありファインチューニングの両方を試すことが可能です。この柔軟性を活かして、様々な設定や手法を実験的に試すことができます。
- ただし、知識容量の制限があるため、特定ドメインや特定タスクへの特化が推奨されます。汎用的な能力と特定分野の深い知識の両方を求めるよりも、どちらかに焦点を絞ったアプローチが効果的です。
中規模モデル
- 継続事前学習とファインチューニングのバランスが特に重要になります。中規模モデルは十分な知識容量を持ちながらも、計算効率が比較的良いという特性があります。
- ドメイン適応のための継続事前学習を中程度実施した後、教師ありファインチューニングを行うアプローチが効果的です。これにより、ドメイン知識と特定タスクへの最適化のバランスを取ることができます。
大規模モデル
- 計算コストが高いため、効率的な学習手法の選択が決定的に重要になります。大規模モデルの全パラメータを更新する学習は、相当な計算リソースを必要とします。
- 大量の継続事前学習よりも、少量の高品質データによる教師ありファインチューニングを優先することが多いです。既に豊富な知識を持つ大規模モデルでは、継続事前学習の追加的な効果が相対的に小さい場合があります。
- PEFT (Parameter-Efficient Fine-Tuning)などの効率的な手法の活用を検討すべきです。LoRA(Low-Rank Adaptation)やプロンプトチューニングなどの手法は、モデル全体のパラメータの一部のみを更新することで、計算効率を大幅に向上させることができます。
モデルサイズの選択自体も重要な決定要素です。プロジェクトの要件、利用可能なリソース、求められる性能レベルなどを総合的に考慮し、適切なサイズのモデルを選択することも、効率的な学習戦略の一部と言えるでしょう。
データ量による戦略の違い
利用可能なデータの量は、学習戦略の選択に大きな影響を与える要素です。データ量によって最適なアプローチが異なるため、プロジェクトの初期段階でデータ資源を評価し、それに基づいた戦略を立てることが重要です。以下では、データ量のカテゴリ別に最適な戦略について説明します。
少量のデータ(数百~数千例)
データが限られている場合、効率的にそれを活用する戦略が必要です。
- 教師ありファインチューニングに集中することが最も効果的です。少量のデータでも、高品質で目的に適合したものであれば、十分な性能向上が期待できます。
- データ拡張技術を積極的に活用することで、実質的なデータ量を増やすことができます。例えば、バックトランスレーション、言い換え生成、ノイズ追加などの手法が有効です。
- 過学習を防ぐための正則化手法の導入も重要です。ドロップアウト、早期停止、重み減衰などの技術を適切に組み合わせることで、限られたデータでも汎化性能を確保できます。
中程度のデータ(数万~数十万例)
中程度のデータ量がある場合、データの種類によってアプローチを調整します。
- 教師ありデータが中心の場合:教師ありファインチューニングを優先し、データの質と多様性を確保することで、モデルの特定タスクでの性能を向上させることができます。
- 教師なしデータが中心の場合:少量の継続事前学習の後に教師ありファインチューニングを行うハイブリッドアプローチが効果的です。まずドメインの言語的特徴を学習させ、その後特定タスクに最適化します。
大量のデータ(数百万例以上)
豊富なデータがある場合、より包括的なアプローチが可能になります。
- 継続事前学習を十分に行った後、教師ありファインチューニングを実施することで、最大限の性能向上が期待できます。特に、ドメイン特化モデルの開発においては、大量のドメイン特化データによる継続事前学習が大きな効果をもたらします。
- データの品質と多様性の確保が重要です。単に量を増やすだけでなく、バランスの取れたデータセットを構築することで、モデルの偏りを減らし、汎化性能を向上させることができます。
実際のプロジェクトでは、これらのカテゴリの境界は必ずしも明確ではありません。また、データの量だけでなく、その質や多様性、目的との適合度なども総合的に考慮することが重要です。限られたデータであっても、それが高品質で目的に適したものであれば、効果的な学習が可能です。逆に、大量のデータでも品質が低ければ、期待通りの結果が得られないことがあります。
表:モデルサイズとデータ量による学習戦略マトリックス
| 少量データ | 中程度データ | 大量データ | |
|---|---|---|---|
| 小規模モデル | 教師ありファインチューニングに集中 データ拡張技術の活用 |
ドメイン特化の継続事前学習 その後の教師ありファインチューニング |
継続事前学習を優先 特定ドメインへの特化 |
| 中規模モデル | PEFT手法を用いたファインチューニング 過学習対策の強化 |
バランスの取れたハイブリッドアプローチ 段階的な学習プロセス |
継続事前学習と教師ありファインチューニングの組み合わせ データ品質の確保 |
| 大規模モデル | 少量高品質データでのPEFT プロンプトチューニングの検討 |
選択的なファインチューニング 効率的なパラメータ更新手法の活用 |
大量データによる継続事前学習 その後の包括的なファインチューニング |
結論とベストプラクティスのまとめ
継続事前学習と教師ありファインチューニングは、LLMの能力を向上させるための相補的なアプローチです。これらの手法を効果的に活用するためには、それぞれの特性を理解し、プロジェクトの目的やリソース制約に応じて適切に使い分けることが重要です。本記事で解説した内容を踏まえ、以下にLLM適応のためのベストプラクティスをまとめます。
ベストプラクティス
目的を明確に定義: プロジェクトの開始時点で、ドメイン知識の獲得が主目的なのか、特定タスクへの最適化が重要なのかを明確にします。継続事前学習は「何を知っているか」を強化し、教師ありファインチューニングは「どう応答するか」のパターンを最適化します。この目的設定が、適切な学習戦略の選択の基盤となります。
データの質と量を検討: 利用可能なデータの特性(教師ありか教師なしか、量、品質、多様性など)を分析し、それに基づいて最適な学習手法を選択します。継続事前学習では大量の無ラベルドメイン特化テキストが必要で、教師ありファインチューニングでは高品質なラベル付きデータが重要です。データの準備プロセスもそれぞれ異なることを理解しましょう。
ハイブリッドアプローチを検討: 可能であれば、継続事前学習と教師ありファインチューニングを組み合わせることで、それぞれの利点を最大限に活かすことができます。多くの実例が示すように、まず継続事前学習でドメイン知識を強化し、次に教師ありファインチューニングでタスク最適化を行う段階的アプローチは、知識と応答能力の両面で優れた結果をもたらします。
計算リソースとのバランス: 利用可能なリソースに応じて学習戦略を調整し、最も効率的なアプローチを選択します。継続事前学習は一般的により多くの計算リソースを必要とし、教師ありファインチューニングは比較的少ないリソースで実施できますが、高品質なラベル付きデータの作成には人的リソースが必要になる場合があります。
以下の表は、継続事前学習と教師ありファインチューニングの主要な特性を比較したものです。
表:継続事前学習と教師ありファインチューニングの特性比較
| 特性 | 継続事前学習 | 教師ありファインチューニング |
|---|---|---|
| 主な目的 | ドメイン知識の獲得・更新 | 特定タスクへの最適化 |
| データ形式 | 無ラベルのドメイン特化テキスト | 入力-出力ペアのラベル付きデータ |
| 学習方法 | 自己教師あり学習(次単語予測) | 教師あり学習(指示に対する応答) |
| 学習率 | 比較的高め(例:5e-5〜1e-4) | 比較的低め(例:1e-5〜2e-5) |
| 計算リソース | 比較的大きい | 比較的小さい |
| 強化される能力 | 「何を知っているか」 | 「どう応答するか」 |
LLMの研究開発は急速に進化しており、継続事前学習と教師ありファインチューニングの手法や応用も日々発展しています。本記事で解説した基本的な概念と原則を理解した上で、最新の研究動向も積極的に取り入れることで、より効果的なLLMの適応が可能になるでしょう。研究コミュニティとの情報交換や実験結果の共有も、この分野の発展に寄与する重要な活動となります。
投稿: 2025/04/12